论文阅读笔记
今天分享一来自 ISSTA 2023 的静态分析文章。Tai-e: A Developer-Friendly Static Analysis Framework for Java by Harnessing the Good Designs of Classics
Tian Tan and Yue Li. 2023. Tai-e: A Developer-Friendly Static Analysis Framework for Java by Harnessing the Good Designs of Classics. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2023). Association for Computing Machinery, New York, NY, USA, 1093–1105. https://doi.org/10.1145/3597926.3598120
b站上有一个静态分析课程,作者基于 tai-e 设计了一个学习性质的静态分析工具,也是非常的有趣。
Abstract
比起静态分析本身的知识,我们对静态分析的框架还知之甚少。
作者比较了许多经典的 Java 的静态分析框架比如 **Soot,Wala,Doop,SpotBugs **,从中选择比较好的框架,如果任何一个都不够好,他们会尽可能地提出一种更好的设计。
这是第一篇系统性的关于 Java 静态分析框架的设计与实现的探索。
Intro
静态分析在非常多的领域做出贡献,比如检测软件缺陷,安全分析,代码优化,程序理解,它还对研究工作和业界的产品有一定的帮助。
然而,尽管静态分析取得了如此巨大的成就,在过去的几十年里出现了许多有名的框架,这些框架却对于想使用这些 analysis 的开发者并不易于学习。换言之,为了构建一个 developer friendly 静态分析框架,这也是非常困难的,往往是对不同目标比如效率,简易度,可用性的一个权衡。
人们对于代码的框架本身却知之甚少,正如 Soot 作者所言:
“We have noticed that it is difficult to publish framework papers… We encourage conferences to accept more framework papers.”
在这方面,作者迈出了一步,讨论了一些静态分析关键组件的一些设计权衡。
- 程序抽象(Program Abstraction):需要提供程序抽象模型,包括 IR,类继承等,为了表示所有程序的要素(静态分析所需的要素)
- 基础分析(Fundamental Analyses):为了让程序提供比较 friendly 的分析框架比如控制流和 call graph 的 graph-based 算法和输入程序的内存抽象信息比如 points-to/alias relations
- 新的分析开发(New Analysis Development):为开发者留的接口,便于实现入安全分析,异常分析,反射分析等
- 对多种分析的管理(Multiple Analyses Management):它应该提供一种标准的方法去管理多种的 analyses,比如当他们(analyses)要一起工作的时候应该怎么协作
考虑了这些,诞生了 Tai-e 这个静态分析框架。 主要有一下的贡献
1. 讨论了经典的静态分析框架,讨论了其合理性,为构建一个更好的静态分析框架提供了一些有用的材料和观点
2. Tai-e 开发友好型静态分析框架。遵循 HGDC 原则。出了来自 HGDC 的创新外,Tai-e 还有一些具体的创新设计,比如:
- 使用友好型 IR,比起 Soot 和 Wala 更加的简洁,更易于理解
- 高效的指针分析,高拓展性
- 创新型的 analysis 插件,易于开发与整合新的 analysis 比如污点追踪异常分析等
Tai-e 最初的目的是有个更 friendly 静态分析框架,使用者的反馈:
An established professor wrote to us: “My students told me that it is very smooth to write code on Tai-e and Tai-e is significantly better than Soot in usability. “
他们还调查了一下一些研究牲,他们尽管使用 Soot/Wala 的时间更长,他们使用了 Tai-e 后认为 Tai-e 更加的 “easy”。他们很多人在使用 Soot/Wala 的过程中提及 functionality 和 debugging 困扰了他们。
很明显 Tai-e 实现了他的目标。
3. Tai-e 影响比较广,他们有开源的代码(https://github.com/pascal-lab/Tai-e),为学习者设计的静态分析代码。吸引了 26 所大学,R&D teams from 13 companies,104 所大学的学生。(这就是开源的力量嘛doge
Program Abstraction
静态分析框架程序抽象模型包括 IR,类型系统,类继承等。接下是对 Tai-e IR 的诠释。
Tai-e 的 IR 很受 Soot 和 Wala 的启发,实现的更加简洁,更便于了解 IR 的隐含信息。(什么 underlying intents of IR,不太理解)

IR 的设计上:Tai-e 区分了赋值表达式的类型
API 设计:在获取表达式时使用了具体的返回类型,避免使用索引
程序元素如值,类型,名字的组织和获取方式:Tai-e 集中了索引变量相关的信息到一个单一接口
在图1中展示了一个 binary statement(e.g.,x=y+z),作为一个方法的 processBinary,分别被 Soot,Wala,Tai-e 描述。
Soot 假定了所有的 statement 内部有一个 “=” 操作符,叫做 AssignStmt 但是没有显式的区分具体的类型。而,AssignStmt 是一个比较底层(lowest-level)的接口,这就导致他需要在第 5 行进行类型判断以保证类型安全。(实话说我当时学 Tai-e 就是疯狂进行类型判断的)。另外,Soot 总是返回 Value(the highest-level 类型继承接口 ),这就导致它必须要强制转换为别的类型,比如第 8 行的 Local 类型,更有趣的例子是 Soot 提供了 IfStmt 的 <Value getCondition()> ,在获取条件表达式时仍然返回 Value,尽管它已经知道这是返回一定是 ConditionExpr。这些例子隐式的区分了 IR 的设计非常的微妙,但是影响很深刻。
Wala 并没有刚刚 Soot 的问题,因为它采用了另外一种表达变量的策略。使用 30 行中的 getUse() 。但是它这样不直观,而且可能增加了调试成本(当需要变量的信息时)。另外,Wala 使用了另外一个接口 ir 以从 op 中获得变量名和类型,这还增加了学习成本。(ir 这个 simbol table 或许有什么妙用呢)
可以预见 Tai-e 因避免了这几个问题而在简洁度和可以理解性上受益。程序中有很多不同类型的 statements 和 expressions,
另外,Tai-e 还有一些新的 IR 设计使它在某些 analyses 中更加容易被接受。比如关联变量 v 和它的 statement,这样当 v 改变的时候,也能获取到它相应的 statement,做进一步的行动。
Fundamental Analyses
静态分析近似关于怎样抽象语义和运行时环境抽象数据。因此,静态分析框架应该提供基本能力来生成此类控制结构,例如(control flow)控制流和(call graph)调用图。
Pointer Analysis (Alias Analysis)
指针分析时非常基础的静态分析,几乎构建了其他所有。
Soot 提供了上下文不敏感(context-insensitive)指针分析 Spark,它高度的优化并且运行很快。Wala 对个上下文敏感(context-sensitive)指针分析进行了优化。不像 Soot,Wala 和 Tai-e,Doop 在Datalog中完全申明和实现,有着更加的 clever 且 useful 的设计,在最近被考虑为实现 proposed 指针分析算法的主流平台。他们都实现了相似的 **Andersen-style **算法。
在设计 Java 静态分析系统时,有一些关键点需要考虑
- 一个 representation 表示 points-to information
- 一个 context manager 以处理上下文敏感(context sensitivity)
- 一个 heap manager 堆管理模型
- 一个 solver 以传播 points-to 信息
前两者 Tai-e 和其他的框架有所不同
representation
Spark 和 Wala 都采用了混合的 points-to set,当 set的大小小于某个具体的值,他就用数组存储,否则使用通常的 bit set 存储。Tai-e 也使用了混合的方法,但是在 bit set 的设计上有一些不一样。
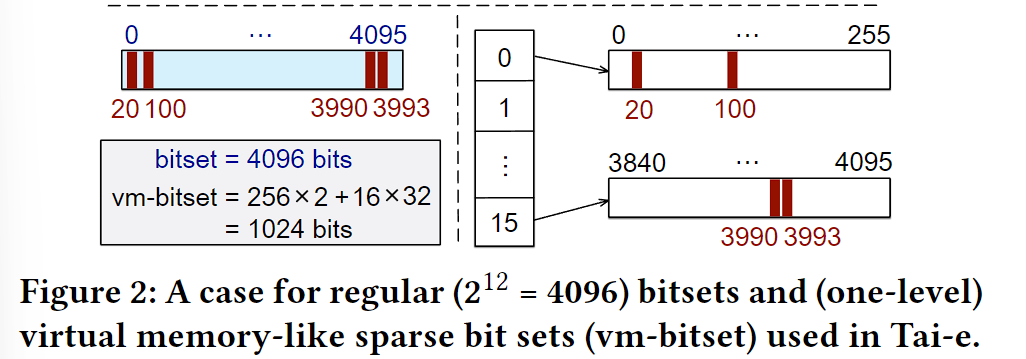
在图2中,右侧的是 Tai-e 的设计,使用了类似虚拟内存的页表思想,他们在实践中往往使用二级页表,在上下文敏感的指针分析中这平均节约了 23%(up to 40%) 的内存。当作者把内存限制为某一个值比如 8G,这有利于 Tai-e 拓展更多的基准。作者注意到 Doop 是申明式的,他的 points-to 集合表示开发者无法获取,并且不同的 Datalog 引擎可能有不同的表示。
context manager
上下文敏感被广泛用于提高 Java 指针分析的精度。作者需要一个管理上下文敏感变量(call-site-,object-,type-sensitivity)的策略。
Soot 没有一个搞笑的上下文敏感指针分析系统,Spark 是一个上下文不敏感的。Paddle 是 Soot 的 BDD-based 上下文敏感指针分析,但是它比 Doop 低效很多,并且它还很久没维护了。Doop 提供了一些优雅的规则以处理上下文敏感,然而因为 Datalog 的限制,对每一个上下文长度,方法调用,堆内存,开发者不得不写一个实现,导致了一些荣誉。(感觉 Doop 也可以有挺好的拓展性)。
与之相反,Tai-e 是命令式的,对于相似的上下文敏感分析实现,它能够轻易的把上下文长度视为输入参数。而 Wala 只提供了函数调用的上下文管理,并且它的堆上下文是直接继承自包含它的调用点(call site)的函数的堆对象。相比于 Wala,Tai-e 在这里更加灵活。
Tai-a 还提供了可选的上下文敏感工具并且在大型和复杂的 Java 程序中也有不错的精度。现在比较先进的可选的指针分析比如 **Zipper ,Zipper𝑒 , Scaler 和 Mahjong **都被 Tai-e 集成进去了,作为一个统一的的指针分析框架以比较不同的上下文敏感分析方法。
Control/Data Flow Analysis
Control Flow Analysis
CFG 尽管基础,但是如何让开发者易于使用,也不容易。
Tai-e 对边进行分类,与 Soot,Wala,Checker 相比分类了比如IF_TRUE,IF_FAUSE,CAUGHT_EXCEPTION 的边类型。尽管他们也可以从相对应的节点或者 IR 中获取边的类型,很不方便就是说。
异常的边对程序分析的影响很大,有两种异常,显式的(throw)与隐式的,显示应当被 catch 处理,隐式的一场被 JVM 抛出,一个完整的 CFG 分析应该包含二者,但是隐式的异常控制流又非常的多并且他们对控制流的影响不是特别大,如果考虑进隐式的异常控制流可能会减小程序的精度和可用性。与 Wala,SpotBugs 和 Checker 不同的是,Tai-e 和 Soot 区分了显式和隐式的异常控制流,允许用户自己添加。
Data Flow Analysis
开发者为了实现数据流分析,通常跟随数据流分析系统的接口来实现,具体有(1)data facts 抽象和初始化(2)让不同 statements 近似的转换函数(3)meet join 操作运算,作为合并 data facts 的依据。
Data facts initialization
Wala 不支持在分析中初始化 data facts,他把相关的 API 放到了 solver 中,在实现分析的过程中导致了不必要的实现(需要去了解 solver 的细节)。
Edge transfer function
Soot 和 Checker 并没有显式地支持 edge transfer function。
Edge transfer 与 node transfer 不同,edge transfer 可以允许不同的 data facts 沿着边传送到后继的 node(节点),利用了分支信息创造了更高效的分析。如果 edge transfer 函数为空,那么这时,分析就回退成为只有 node transfer 函数的分析。在 Soot 中,它为了处理分支信息,开发者需要拓展一个特殊的 analysis 叫做 BranchedFlowAnalysis 而且还要实现其 edges 和 nodes 的逻辑,这很不方便,在设计上也有一些繁琐。 Checker 也不显式地支持 edge tansfer,但是他在处理 node transfer 中区分了不同的类型,比如 then 和 else branches。求解器会沿着这个传播信息。
Checker 与其他架构有所不同,它通过允许开发者给 type 写 qualifiers(尤其是 Java annotations),增强了 Java 的类型系统,这种方法在实践中提高了分析的效率。他们(Tai-e)可能会在这方面继续做一些研究,如何合并进这种类型系统。
NEW ANALYSIS DEVELOPMENT
静态分析框架应该提供一个机制以合并进新的 analyses,包括过程内和过程间的分析。Tai-e 支持这些功能使得其易于开发和并入新的 analysis。
Past Work
Doop 很自然地支持 interactive analysis(指的应该是要和指针分析交互的分析如 reflection analysis,exception analysis等)并且能够产生优雅的实现,Doop 从 Datalog 的申明式能力中获益,然而 Doop 也受限于 Datalog 在实现 analysis 时需要 not-set-based lattices。(不懂),并且由于 Datalog solver 采用了 analysis-independent 数据结构和执行策略,它比较难对具体的 analyses 优化。最终,推进交互分析的命令式框架有很高的呼声。作为代表,Soot 缺少了这一部分而 Wala 做到了一定程度。
Wala 提供了一个添加新的可以和 pointer analysis 交互的 analysis 的方法,但是有一定的限制,简单地说,开发者需要实现一个叫做 ContextSelector 的接口来具体说明相关的调用点(call site)。举例来说,为了分析反射的调用 v=c.newInstance(),开发者需要编写 ContextSelector以识别这个 call site 并且获取被 c 指向的 Class objects,称作 CO,然后开发者需要实现 ContextInterpreter 以生成不同的虚构但是等效的 IRs,根据从 CO 中分析出的类型,叫做T。然后这些生成的 IRs 回到指针分析中维持反射调用的清晰度(resolution)。
这个方法非常的直白但是对指针分析的交互促进有一定的限制。
- 对于具体的分析,开发者只能专注于并解决相关的 call site;监视特定变量的 points-to information 的能力是需要的,举例来说,在异常分析中,如果变量 e points-to 集合在 throw 的过程中被改变了,相应于 catch 变量的 points-to 集合就应被更新了。
- 在许多情况下直接更新调用图边或points-to 集合更简单,这可以防止创建过多的虚假 IR,并且调用求解器重新分析创建的代码。
Helm 等人提出一种动态写作各种分析的方法,即使具有不同的分析格。但是这种方法过于复杂无法解决作者的问题。(解决的主要问题不是 friendly 嘛,这本身就有一点矛盾的)
为了从实践上促进新 analysis(那些需要和指针分析交互的 analysis)的开发,在 Tai-e 中,作者提出一种简单且搞笑的方法 analysis plugin system。当前有很多基于这个系统的插件,包括了基础的比如反射和异常分析,客体比如污点追踪分析,公共工具比如 analysis timer 和 constraint checker。
Basic Idea
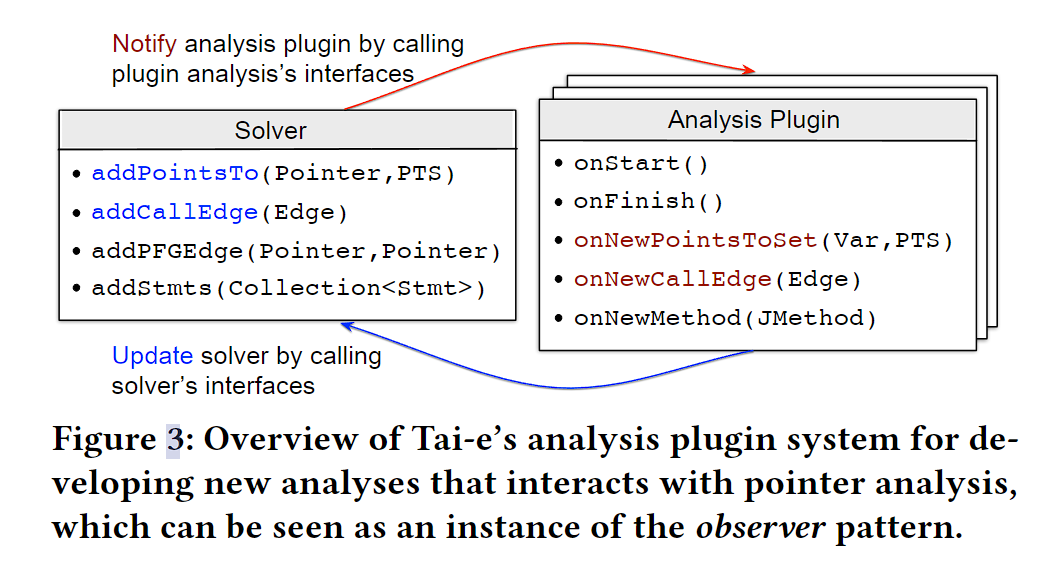
接下来解释 analysis plugin system 怎么工作。如图3,这个系统包含了一个指针分析 solver 和一些用户定义的分析与前者交互。Solver 和 Plugin 的核心被分别高亮为蓝色和红色,开发者只需要实现和 Plugin 相关的 APIs 就可以开发新的 analysis。额外的辅助 API 比如 addStmt(模拟调用的效果,和前问提及的 Wala 相似)使得创建具体的功能更加简单。
让我们阐述它的基本工作机制,驱使那些核心的 APIs。假定你在实现某个 analysis Plugin 的onNewPointsToSet 方法,当变量 Var 的 points-to set(PTS)改变了,你需要写处理相关的副作用的逻辑。结果就是,你需要更新和指针相关的 PTS,或者添加一个 call graph edges 相关的 call sites。因此,在实现 onNewPointsToSet 时,你需要调用 addPointsTo 或者 addCallEdge 方法来提示这些变化。
相反的说,在分析的迭代中,Solver 会自动的调用 onNewPointsToSet 和 onNewCallEdge 方法来提示变量(Var,PTS)可能发生的改变。最终,开发者只需要 Plugin 的几个模块就可以实现目的了。
Case Study

为了更好的理解怎样构建新的 analyses ,作者给了一个例子,如图4。
下面是一个污点追踪的例子。
1 String s1 = x.source();
2 s3 = s2.concat(s1);
3 y.sink(s3);x.source() 返回了一个对象 o1,o1 又被混合成为 o3,o3 被 s3指向,s3 由 s2.concat(s1) 返回,污点追踪报告了第三行包含泄露 o1(敏感数据),当 o3 被一个 sink 方法调用时。
因为污点追踪被开发为一个 analysis 插件,他需要实现一些 Plugin 的方法,在图4中,实现了 onNewCallEdge(3行),onNewPointsToSet(12行)和辅助函数 onFinish(21行)。
对于 onNewCallEdge,假定我们在处理第一行 call site(String s1=x.source()),对于这个调用点,指针分析已经创建了从 edge source(被表示为 edge.cs 的 call site)到edge target 的新的 call graph,然后求解器通知污点追踪插件并且传入作为参数的新边(3行),通过调用插件的 onNewCallEdge 函数。
然后插件检查 edge.target。如果 target 是一个敏感的方法,是 source(图4第4行)。一个污点对象就被创建了(5行),然后插件给 solver 更新了那个 call site 的 left-hand 变量(edge.cs.lhsV),叫做 s1(6行),s1应该指向刚创建的污点对象。
如果 target 是一个 transfer 方法(7行),他就会把污点传到其他的对象中。(忽略一点点论文细节)
MULTIPLE ANALYSES MANAGEMENT
很多情况下,一个分析依赖于另一个分析的输出,如果提供这种机制,对框架非常有帮助。接下来是关于增氧配置 analysis 依赖和怎样保存一个 analysis 的输出并且从另外的地方访问。
Configure Analysis and its Dependencies
Wala 没有显式的管理来进行多重分析。在 Soot 中,为了添加新的分析,开发者需要硬编码代码进 Soot 中,而 Tai-e 支持通过配置文件注册框架中所以的新分析(及其依赖关系),然后通过反射自动驱动它们,这样解耦了代码。此外 Soot 在运行分析之前,用户需要明确列出任何依赖分析,这样比较麻烦而且不熟悉框架的人容易出错。而在 Tai-e 中依赖关系是通过配置文件自动生成的,确保所有依赖分析正常执行。与 SpotBugs 相比,Tai-e 在解析分析依赖关系方面更加灵活,通过支持条件逻辑来描述分析选项和依赖关系。
Store/Access Analysis Results.
这虽然看上去是一个微不足道的细节,但是也能影响使用者的体验。Soot 只能存储一些指针分析结果在 singleton instance of Scene,SpotBugs 中用户需要记住不同方法和参数以获得多样的 analysis 的相关的结果。在 Tai-e 中,用户只要记得一个方法 getResult(id) 就可以了。(id 是分析的名字和配置),而且这是对于所有类型的分析,包括了 method-,class- 和 program-level analyses。用户不再需要担心记忆复杂的方法,并且使用额外的参数来获得结果。
EVALUATION
Tai-a 的优点在前文基本都讲过,缺点也有一些。
- 文档比较少
- 生态不够完善
- 可能某种程度上不够灵活,比如 plugin system 不能重写 visitXXX() 函数。
人们仍然非常关注效率,尽管 Tai-e 的目标是 user-friendly 。作者使用了所有的标准 Java DaCapo benchmarks 加上一些在最近的文章中经常使用的 real-world 应用。
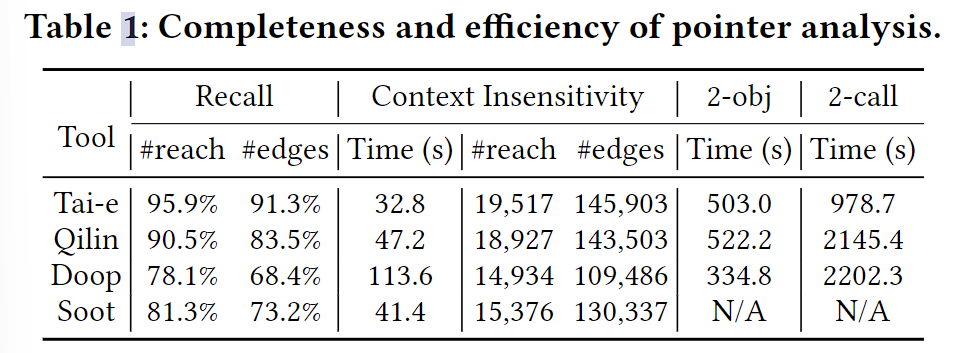
在指针分析中,如表1,Tai-e 比起其他有着更好的 Recall,效率上也更高,得益于反射的精度,native code modeling,以及很多指针分析实现上的优化。
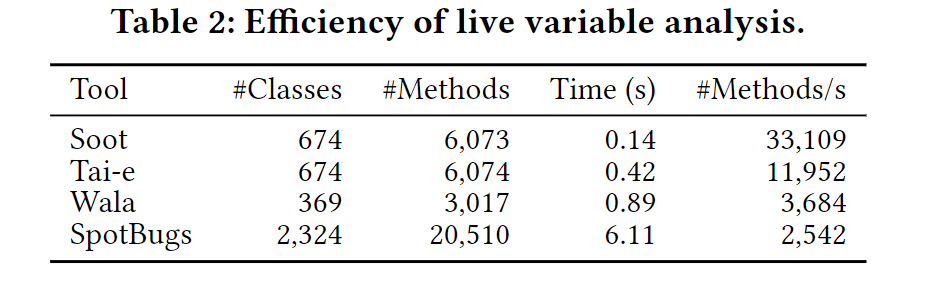
在数据流分析中,作者又展示了表2中的平均数据。Tai-e 在这个分析中不如 Soot 但是比 Wala 和 SpotBugs 好,他们分析 Soot 在数据流分析中有比较复杂的优化,而这种优化在 Tai-e 中没有。(怎么有一种未来可期的感觉)
RELATED WORK
强相关的在前文已经提及,在这里讨论一些额外的相关的工作。
Lam et al. 回顾了 Soot,总结了它的主要的特征和挑战(联合单个以支持多重的分析,分析不完整的程序等),未来的方向(构建更快的 startup,提高过程间分析能力),另外他们还提及一些开发 Soot 中的困难,建议了一些未来编译器的框架。
Schubert et al. 描述了构建 C/C++ 分析框架的经验,有一部分用于特定的框架,而另一部分比较通用。比如它提供了 meas like instruction 帮助调试 analysis-related bugs,Tai-e 考虑整合进这个。
Sadowski et al. 总结了在 Google 构建静态分析工具的经验。它建议尽早合并静态分析进工作流,尽可能把 analysis check 当作编译器报错来做(否则开发者经常遗忘分析的结果)。
来自 Facebook 的研究表明过程间分析对发现深层的 bugs 和安全漏洞的价值。Tai-e 的 analysis plugin system 被专门设计了,为了让开发很多复杂的与指针分析交互的过程间分析,比如精准的 virtual-call 处理和 static value-flow tracking。
一些研究用用户视角的方式评估静态分析工具,比如,一个好的静态分析工具应该有高质量的警告信息尽管这提供的信息可能有错误、为什么这里应该被修复、这应该专门修复等。
Chord 是一个由 Java 和 Datalog bddbddb 写的 Java 静态分析框架,作为 Datalog 的solver。Datalog 的优劣在前文已经讲述过了。Chord 因检测同步问题比如数据竞争的能力而知名。Tai-e 将会命令式的(imperatively)开发这些客户端。
OPAL 是一个由 Scala 写的 Java 静态分析框架。不幸的是对于作者来说很难和 OPAL 实现的静态分析协作。另外 OPAL 的作者主导了一个有趣的调查不同框架的 call graphs 的 soundness ,强调了有效实现语言特征的有效性。
Tai-e 的某些设计受 TAJS 的启发,TAJS 是一个经典的 JavaScript 和 Node.js 静态分析框架, 其中之一是回归测试,另一个是 analysis plugin system 的初始的思想。solver plugins 结构和 TAJS 的monitor approach 比较相似,尽管他们的目标不太一样。
CONCLUSIONS
尽管静态分析发展了很多并且在过去几十年出现了一些知名的工具。对于那些依赖框架需要构建 analyses 的开发者,这些框架并不那么简单去学习和使用,因为构建一个开发者有好的静态分析框架并非易事。这篇文章在这方面前进了一步,通过系统的比较和讨论关键组件设计的权衡 Java 静态分析框架,遵循了 HGDC 原则。
对于每一个设计点,作者的努力是比较多 labor- 和 intelligence-intensive。他们必须比较充满复杂 analysis algorithms 的实现的大型且复杂的框架的代码。但是这些是非常值得的,因为这些帮助了 Tai-e 的诞生。且 Tai-e 达成了自己的目的 friendly。作者希望这个工作能够给静态分析基础提供比较有用的资料和观点,他们也会积极持续的开发 Tai-e,在未来合并进更多的 analyses 和 clients。